|
|
1. 數(shù)據(jù)庫的數(shù)據(jù)存儲(chǔ)
1.1文件:
我們一旦創(chuàng)建一個(gè)數(shù)據(jù)庫,都會(huì)生成兩個(gè)文件:
DataBaseName.mdf: 主文件,這是數(shù)據(jù)庫中的數(shù)據(jù)最終存放的地方。
DataBaseName.ldf:日志文件,由數(shù)據(jù)操作產(chǎn)生的一系列日志記錄。
1.2分區(qū):
在一個(gè)給定的文件中,為表和索引分配空間的基本存儲(chǔ)單位。 1個(gè)區(qū)占64KB,由8個(gè)連續(xù)的頁組成。 如果一個(gè)分區(qū)已滿,但需存一條新的記錄,那么該記錄將占用整個(gè)新分區(qū)的空間。
1.3 頁:
分區(qū)中的一個(gè)分配單位。這是實(shí)際數(shù)據(jù)行最終存放的地方。 頁用于存儲(chǔ)數(shù)據(jù)行。
Sql Server有多種類型的頁:
Data, Index,BLOB,GAM(Global Allocation Map),SGAM,PFS(Page Free Space),IAM(Index Allocation Map),BCM(Bulk Changed Map)等。
2. 索引
2.1.1索引
索引是與表或視圖關(guān)聯(lián)的磁盤上結(jié)構(gòu),可以加快從表或視圖中檢索行的速度。索引包含由表或視圖中的一列或多列生成的鍵。這些鍵存儲(chǔ)在一個(gè)結(jié)構(gòu)(B 樹)中,使 SQL Server 可以快速有效地查找與鍵值關(guān)聯(lián)的行。
通俗點(diǎn)說,索引與表或視圖相關(guān),旨在加快檢索速度。索引本身占據(jù)存儲(chǔ)空間,通過索引,數(shù)據(jù)便會(huì)以B樹形式存儲(chǔ)。因此也加快了查詢速度。
2.1.2聚集索引
聚集索引根據(jù)數(shù)據(jù)行的鍵值在表或視圖中排序和存儲(chǔ)這些數(shù)據(jù)行。索引定義中包含聚集索引列。每個(gè)表只能有一個(gè)聚集索引,因?yàn)閿?shù)據(jù)行本身只能按一個(gè)順序排序。只有當(dāng)表包含聚集索引時(shí),表中的數(shù)據(jù)行才按排序順序存儲(chǔ)。如果表具有聚集索引,則該表稱為聚集表。如果表沒有聚集索引,則其數(shù)據(jù)行存儲(chǔ)在一個(gè)稱為堆的無序結(jié)構(gòu)中。
通俗點(diǎn)說,聚集索引的頁存儲(chǔ)的是實(shí)際數(shù)據(jù)。每個(gè)表只能建立唯一的聚集索引,但也可以沒有。
如果建立聚集索引,那么表中數(shù)據(jù)以B樹形式存儲(chǔ)數(shù)據(jù)。
對(duì)于聚集索引的理解,打個(gè)比方,即英文字典的單詞編排。 英文字典單詞以A,B,C,D….X,Y,Z的形式順序編排,如果我們查找 Good 單詞,我們首先定位到G,然后定位o – o-d. 最終查找到Good,便是good實(shí)際存在的地方。建聚集索引需要至少相當(dāng)該表120%的附加空間,以存放該表的副本和索引中間頁。
2.1.3非聚集索引
非聚集索引具有獨(dú)立于數(shù)據(jù)行的結(jié)構(gòu)。非聚集索引包含非聚集索引鍵值,并且每個(gè)鍵值項(xiàng)都有指向包含該鍵值的數(shù)據(jù)行的指針。
從非聚集索引中的索引行指向數(shù)據(jù)行的指針稱為行定位器。行定位器的結(jié)構(gòu)取決于數(shù)據(jù)頁是存儲(chǔ)在堆中還是聚集表中。對(duì)于堆,行定位器是指向行的指針。對(duì)于聚集表,行定位器是聚集索引鍵。
通俗點(diǎn)說,非聚集索引的頁存儲(chǔ)的是不是實(shí)際數(shù)據(jù),而是實(shí)際數(shù)據(jù)的地址。一個(gè)表可以存在多個(gè)非聚集索引。在Sql Server2005中,每個(gè)表最多可以建立249個(gè),而在Sql server2008中,則最多可以建立999個(gè)非聚集索引。
對(duì)于非聚集索引的理解,即新華字典的“偏旁部首”查字法。遇到您不認(rèn)識(shí)的字,不知道它的發(fā)音,這時(shí)候,您就不能按照剛才的方法找到您要查的字,而需要去根據(jù)“偏旁部首”查到您要找的字,然后根據(jù)這個(gè)字后的頁碼直接翻到某頁來找到您要找的字。
但您結(jié)合“部首目錄”和“檢字表”而查到的字的排序并不是真正的正文的排序方法,比如您查“張”字,我們可以看到在查部首之后的檢字表中“張”的頁碼是672頁,檢字表中“張”的上面是“馳”字,但頁碼卻是63頁,“張”的下面是“弩”字,頁面是390頁。很顯然,這些字并不是真正的分別位于“張”字的上下方,現(xiàn)在您看到的連續(xù)的“馳、張、弩”三字實(shí)際上就是他們在非聚集索引中的排序,是字典正文中的字在非聚集索引中的映射。我們可以通過這種方式來找到您所需要的字,但它需要兩個(gè)過程,先找到目錄中的結(jié)果,然后再翻到您所需要的頁碼。我們把這種目錄純粹是目錄,正文純粹是正文的排序方式稱為“非聚集索引”。
2.1.4 覆蓋索引:
覆蓋索引是指那些索引項(xiàng)中包含查尋所需要的全部信息的非聚集索引,這種索引之所以比較快也正是因?yàn)樗饕撝邪瞬閷に仨毜臄?shù)據(jù),不需去訪問數(shù)據(jù)頁。 如果非聚簇索引中包含結(jié)果數(shù)據(jù),那么它的查詢速度將快于聚集索引。
但是由于覆蓋索引的索引項(xiàng)比較多,要占用比較大的空間。而且update 操作會(huì)引起索引值改變。所以如果潛在的覆蓋查詢并不常用或不太關(guān)鍵,則覆蓋索引的增加反而會(huì)降低性能。
2.1.5 主鍵和索引
主鍵:表通常具有包含唯一標(biāo)識(shí)表中每一行的值的一列或一組列。這樣的一列或多列稱為表的主鍵 (PK),用于強(qiáng)制表的實(shí)體完整性。在創(chuàng)建或修改表時(shí),您可以通過定義 PRIMARY KEY 約束來創(chuàng)建主鍵。 它是一種唯一索引。
下面是一個(gè)簡單的比較表
| 主鍵 | 聚集索引 |
用途 | 強(qiáng)制表的實(shí)體完整性 | 對(duì)數(shù)據(jù)行的排序,方便查詢用 |
一個(gè)表多少個(gè) | 一個(gè)表最多一個(gè)主鍵 | 一個(gè)表最多一個(gè)聚集索引 |
是否允許多個(gè)字段來定義 | 一個(gè)主鍵可以多個(gè)字段來定義 | 一個(gè)索引可以多個(gè)字段來定義 |
|
|
|
是否允許 null 數(shù)據(jù)行出現(xiàn) | 如果要?jiǎng)?chuàng)建的數(shù)據(jù)列中數(shù)據(jù)存在null,無法建立主鍵。 | 沒有限制建立聚集索引的列一定必須 not null . |
是否要求數(shù)據(jù)必須唯一 | 要求數(shù)據(jù)必須唯一 | 數(shù)據(jù)即可以唯一,也可以不唯一。看你定義這個(gè)索引的 UNIQUE 設(shè)置。 |
|
|
|
創(chuàng)建的邏輯 | 數(shù)據(jù)庫在創(chuàng)建主鍵同時(shí),會(huì)自動(dòng)建立一個(gè)唯一索引。 | 如果未使用 UNIQUE 屬性創(chuàng)建聚集索引,數(shù)據(jù)庫引擎 將向表自動(dòng)添加一個(gè)四字節(jié) uniqueifier 列。 |
2.2 索引的存儲(chǔ)結(jié)構(gòu)
2.1.1 整表掃描和索引掃描
整表掃描和索引掃描是Sql Server數(shù)據(jù)庫檢索到數(shù)據(jù)的唯一的兩種方式。除此之外,沒有第三種方式供Sql Server檢索到數(shù)據(jù)。
整表掃描
最直接的檢索方式, Sql Server進(jìn)行表掃描時(shí),會(huì)從表頭開始掃描,直到整個(gè)表結(jié)束。 當(dāng)找到符合條件的記錄,便把該記錄存在結(jié)果集中。對(duì)于小數(shù)據(jù)量的表,這是一種很快捷的方式。如果沒有為表創(chuàng)建索引,那么Sql server便按這種方式檢索數(shù)據(jù)。
索引掃描
如果為表創(chuàng)建了索引,在進(jìn)行檢索前,Sql Server優(yōu)化器會(huì)根據(jù)查詢條件,從可用的索引中選擇最優(yōu)化的索引。檢索時(shí),便會(huì)遍歷B樹,當(dāng)找到符合條件的記錄,便把該記錄存在結(jié)果集中。因此,檢索大數(shù)據(jù)量的表,使用索引相對(duì)于整表掃描會(huì)顯著地提高性能。
2.1.2 B-Tree 
2.2.3 聚集索引
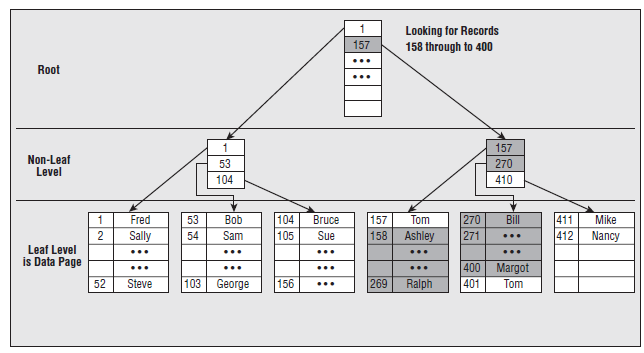
葉子節(jié)點(diǎn)存放的是實(shí)際的數(shù)據(jù)。索引的入口點(diǎn)存放在master->sys.indexes中。
2.2.4 非聚集索引
2.4.1 堆上的非聚集索引(Non-clustered index on heap)
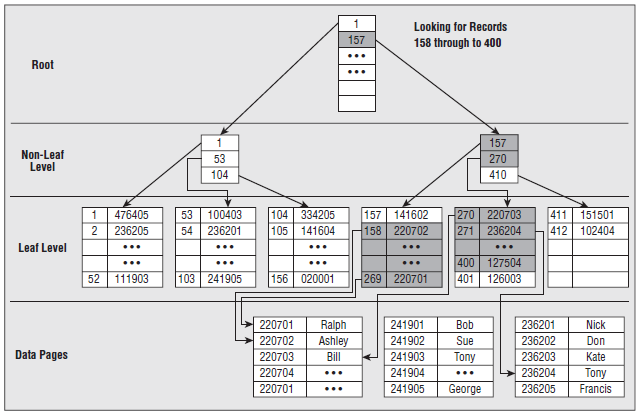
與聚集索引很類似。不同處在:葉子節(jié)點(diǎn)存放的不是實(shí)際數(shù)據(jù),而是指向?qū)嶋H數(shù)據(jù)的指針。檢索速度非常接近于聚集索引,比起聚集索引,實(shí)際上只是多一步由根據(jù)指針檢索到實(shí)際數(shù)據(jù)的過程。
2.4.2 聚集表上的非聚集索引
3. 管理索引
3.1 創(chuàng)建 it知識(shí)庫:數(shù)據(jù)庫索引,你該了解的幾件事,轉(zhuǎn)載需保留來源! 鄭重聲明:本文版權(quán)歸原作者所有,轉(zhuǎn)載文章僅為傳播更多信息之目的,如作者信息標(biāo)記有誤,請(qǐng)第一時(shí)間聯(lián)系我們修改或刪除,多謝。CREATE [UNIQUE] [CLUSTERED|NONCLUSTERED]
INDEX <index name> ON <table or view name>
(<column name> [ASC|DESC] [,...n])
INCLUDE (<column name> [, ...n])
[WITH
[PAD_INDEX = { ON | OFF }]
[[,] FILLFACTOR = <fillfactor>]
[[,] IGNORE_DUP_KEY = { ON | OFF }]
[[,] DROP_EXISTING = { ON | OFF }]
[[,] STATISTICS_NORECOMPUTE = { ON | OFF }]
[[,] SORT_IN_TEMPDB = { ON | OFF }]
[[,] ONLINE = { ON | OFF }
[[,] ALLOW_ROW_LOCKS = { ON | OFF }
[[,] ALLOW_PAGE_LOCKS = { ON | OFF }
[[,] MAXDOP = <maximum degree of parallelism>
]
[ON {<filegroup> | <partition scheme name> | DEFAULT }]