|
|
前段時(shí)間把公司的主數(shù)據(jù)庫(kù)切了,分成業(yè)務(wù)庫(kù)和報(bào)表庫(kù),業(yè)務(wù)庫(kù)向報(bào)表庫(kù)進(jìn)行實(shí)時(shí)的Replication。這個(gè)項(xiàng)目的上線提升了系統(tǒng)的性能和可維護(hù)性,現(xiàn)在把設(shè)計(jì)時(shí)的考量和所做的工作重新回顧一下,作為備忘。
項(xiàng)目起源
在日常的開(kāi)發(fā)過(guò)程中,功能總是先于性能被考慮。只有當(dāng)用戶抱怨系統(tǒng)性能時(shí),我們才開(kāi)始頭痛醫(yī)頭,腳痛醫(yī)腳地來(lái)解決這些性能問(wèn)題。
公司的CRM和ERP系統(tǒng)叫作Olite,完全是我們組開(kāi)發(fā)的。從無(wú)到有,功能不斷擴(kuò)展,原先只有CRM模塊,后來(lái)加入了ERP模塊,Accounting功能和Report功能。近來(lái)出現(xiàn)的情況是當(dāng)某些用戶跑一個(gè)大Report時(shí),正在進(jìn)行業(yè)務(wù)操作的用戶感覺(jué)系統(tǒng)響應(yīng)非常慢。通過(guò)對(duì)系統(tǒng)的性能監(jiān)視發(fā)現(xiàn),在這些時(shí)刻,數(shù)據(jù)庫(kù)中產(chǎn)生了大量的鎖,同時(shí)服務(wù)器上出現(xiàn)了CPU和內(nèi)存資源消耗的尖峰。
系統(tǒng)結(jié)構(gòu)
性能問(wèn)題源于系統(tǒng)的整體結(jié)構(gòu)和發(fā)展過(guò)程。Olite系統(tǒng)的Application是基于.NET平臺(tái)的Web Form程序,數(shù)據(jù)庫(kù)為SQL Server 2005。其主體結(jié)構(gòu)如下圖所示:
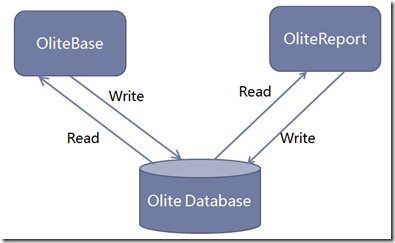 其Application端包括兩個(gè)網(wǎng)站:OliteBase和OliteReport,但連接的都是同一個(gè)數(shù)據(jù)庫(kù)。
其Application端包括兩個(gè)網(wǎng)站:OliteBase和OliteReport,但連接的都是同一個(gè)數(shù)據(jù)庫(kù)。
Olite的Application端其實(shí)很薄,而把大量的業(yè)務(wù)邏輯包裝在存儲(chǔ)過(guò)程中,放在數(shù)據(jù)庫(kù)端來(lái)運(yùn)行。
這種結(jié)構(gòu)在起初性能很好,而且提供給用戶的Report是實(shí)時(shí)的業(yè)務(wù)數(shù)據(jù)。但隨著提供的業(yè)務(wù)模塊,特別是Report的增多(Report對(duì)應(yīng)的存儲(chǔ)過(guò)程連接的表多,計(jì)算量大,輸出的結(jié)果集大),數(shù)據(jù)庫(kù)就成為了瓶頸。
首先,我們做了存儲(chǔ)過(guò)程的優(yōu)化,通過(guò)創(chuàng)建Trace捕獲性能差的存儲(chǔ)過(guò)程,并對(duì)其進(jìn)行優(yōu)化。我們這么做了一段時(shí)間,但獲得的收效并不大。我們?cè)趦?yōu)化以往存儲(chǔ)過(guò)程的同時(shí),隨著系統(tǒng)新功能的上線,又有新的存儲(chǔ)過(guò)程進(jìn)入需要優(yōu)化的列表中。
其次,修改數(shù)據(jù)庫(kù)設(shè)計(jì),其中包括修改表結(jié)構(gòu)和優(yōu)化索引。在系統(tǒng)局部重構(gòu)表結(jié)構(gòu)與關(guān)系對(duì)于性能的提升還是比較明顯的,但這樣的修改會(huì)造成Application端的大量修改,工作量大,風(fēng)險(xiǎn)大,所以不能大規(guī)模實(shí)施。對(duì)于索引優(yōu)化又存在矛盾,業(yè)務(wù)模塊(OliteBase)要求數(shù)據(jù)庫(kù)中的索引不要太多,以支持高效的插入、修改和刪除,而報(bào)表模塊(OliteReport)則希望在數(shù)據(jù)庫(kù)中有更多的索引,以支持高效讀。
最后,我們還試圖提供晚一天的Report服務(wù),來(lái)分流主數(shù)據(jù)庫(kù)的壓力。每天通過(guò)把前一天的備份數(shù)據(jù)庫(kù)恢復(fù)在另一臺(tái)服務(wù)器上,并在此服務(wù)器上提供OliteReport2站點(diǎn),給用戶提供Report服務(wù)。但用戶并不喜歡使用OliteReport2,原因分析下來(lái)有3個(gè)方面:其一,有時(shí)用戶確實(shí)需要實(shí)時(shí)的Report。其二,OliteReport能存儲(chǔ)用戶的Report條件,而OliteReport2由于每天都會(huì)被刷新,無(wú)法保留這些條件。其三,用戶更習(xí)慣打開(kāi)原來(lái)的Report鏈接。
項(xiàng)目需求
上述的各種優(yōu)化方案都沒(méi)有根本性的解決系統(tǒng)的性能問(wèn)題。在這種的背景下我們有了把報(bào)表數(shù)據(jù)庫(kù)與業(yè)務(wù)數(shù)據(jù)庫(kù)分離的想法。
此項(xiàng)目的需求:
1. 提高用戶對(duì)整個(gè)系統(tǒng)性能的感受,Report模塊不要影響到業(yè)務(wù)模塊的運(yùn)行。
2. 用戶可以和原先一樣使用Report模塊,即不增加新的Report站點(diǎn)。
3. 用戶可以和原先一樣存儲(chǔ)填寫(xiě)的Report條件,以供重復(fù)使用。
4. 盡可能提供最小延時(shí)的Report。
需求1是這個(gè)項(xiàng)目的主要目標(biāo),需求2、3、4是盡可能保證項(xiàng)目所帶來(lái)的改變對(duì)用戶是透明的。
方案選擇
對(duì)于原來(lái)的系統(tǒng)結(jié)構(gòu),其Application端已經(jīng)是兩個(gè)獨(dú)立的站點(diǎn)OliteBase和OliteReport。所以只要把OliteBase和OliteReport的數(shù)據(jù)庫(kù)進(jìn)行分離,在分離后的兩數(shù)據(jù)庫(kù)間進(jìn)行數(shù)據(jù)的同步就行了。這里的關(guān)鍵在于如何進(jìn)行數(shù)據(jù)庫(kù)間的同步。
微軟提供了很多種數(shù)據(jù)同步的選擇:1.集群;2.Log Shipping;3.Replication;4.Mirror;5.Integration Service。
微軟提供的這些方案中大部分都是用于做數(shù)據(jù)庫(kù)的高可用性的,而我們的項(xiàng)目是以高性能為目標(biāo)的。為了滿足我們自己的需求,應(yīng)選擇那種方案,并做哪些修改呢?
1.集群
這是第一個(gè)被我們否決的方案。配置SQL Server數(shù)據(jù)庫(kù)集群,對(duì)硬件有較多限制,而且配置相對(duì)其他方案復(fù)雜。我們的項(xiàng)目總共的服務(wù)器資源就兩臺(tái),除原先主數(shù)據(jù)庫(kù)服務(wù)器外,另一臺(tái)是虛擬機(jī)。
2.Log Shipping
Log Shipping把主數(shù)據(jù)庫(kù)的日志傳送到從數(shù)據(jù)庫(kù),并在從數(shù)據(jù)庫(kù)上進(jìn)行回放來(lái)保證主、從數(shù)據(jù)庫(kù)間數(shù)據(jù)的一致,從數(shù)據(jù)庫(kù)為只讀。Log Shipping而且還有配置簡(jiǎn)單的特點(diǎn),開(kāi)始時(shí)是我們的一個(gè)候選方案,但在進(jìn)一步的實(shí)驗(yàn)過(guò)程中發(fā)現(xiàn)了兩個(gè)問(wèn)題。第一、Log Shipping可設(shè)置的時(shí)間間隔最小單位為分鐘。第二、當(dāng)從數(shù)據(jù)庫(kù)進(jìn)行日志回放時(shí),連接此數(shù)據(jù)庫(kù)的連接需要被斷開(kāi)。其中第二個(gè)問(wèn)題是難以容忍的,這個(gè)方案也被淘汰了。
3.Replication
Replication的原理和Log Shipping有些相似,但其提供了更多的靈活性。Replication可以只多主數(shù)據(jù)庫(kù)的一些表、函數(shù)或存儲(chǔ)過(guò)程進(jìn)行,甚至可以對(duì)某些符合條件的記錄進(jìn)行。除此之外,其復(fù)制出來(lái)的數(shù)據(jù)庫(kù)可寫(xiě),而且復(fù)制的最小時(shí)間間隔可配置為concurrent(測(cè)試下來(lái)的時(shí)間延遲為秒級(jí)別),而且其配置也較為簡(jiǎn)單。經(jīng)過(guò)一些實(shí)驗(yàn),我們最后選擇了它。后面會(huì)對(duì)其原理和配置進(jìn)一步討論。
4.Mirror
Mirror是SQL Server 2005提供的強(qiáng)大的高可用性方案。其鏡像數(shù)據(jù)庫(kù)不能直接讀取,這和我們的需求場(chǎng)景不符合,所以被否了。
5.Integration Service
Integration Service具有最大的靈活性,其可以為數(shù)據(jù)倉(cāng)庫(kù)進(jìn)行數(shù)據(jù)抽取,轉(zhuǎn)換和裝載。但使用Integration Service需要有大量的開(kāi)發(fā)與測(cè)試工作,所以我們也沒(méi)選用。
Replication方案細(xì)分
Replication方案又可以分為Snapshot Replication, Transactional Replication, Peer-2-Peer Replication, Merge Replication。
Snapshot Replication:一般用于對(duì)于數(shù)據(jù)庫(kù)的一次性的完全復(fù)制。
Transactional Replication:用于主數(shù)據(jù)庫(kù)向從數(shù)據(jù)庫(kù)的單向復(fù)制。
Peer-2-Peer Replication:能進(jìn)行二個(gè)或多個(gè)數(shù)據(jù)庫(kù)之間的互相復(fù)制,即從數(shù)據(jù)庫(kù)也能向主數(shù)據(jù)庫(kù)復(fù)制,這個(gè)功能很強(qiáng)大,但可能會(huì)引起沖突,需要特別關(guān)注保證各庫(kù)的數(shù)據(jù)完整性。
Merge Replication:可以把多個(gè)數(shù)據(jù)庫(kù)中的數(shù)據(jù)進(jìn)行合并后,復(fù)制到目標(biāo)數(shù)據(jù)庫(kù)。
對(duì)于我們的需求,我們選用了最單純的Transactional Replication。
Transactional Replication原理
在Transactional Replication中有3個(gè)角色:Publisher(發(fā)布者), Distributor(分發(fā)者), Subscriber(訂閱者)。其邏輯圖如下:
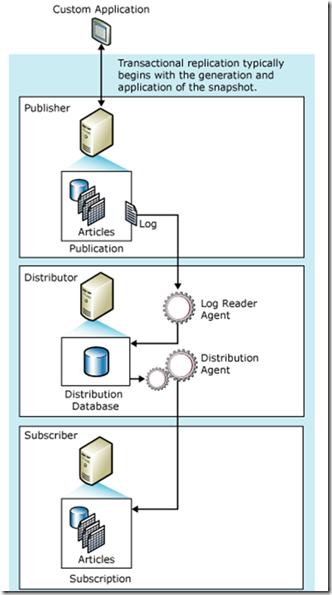 在進(jìn)行增量的Transactional Replication之前,Subscriber需要進(jìn)行初始化,使其包含和Publisher一樣的表結(jié)構(gòu)和初始數(shù)據(jù)。
在進(jìn)行增量的Transactional Replication之前,Subscriber需要進(jìn)行初始化,使其包含和Publisher一樣的表結(jié)構(gòu)和初始數(shù)據(jù)。
Transactional Replication啟動(dòng)之后,Distributor上的Log Reader Agent會(huì)將讀取Publisher的Log信息,并分揀出被標(biāo)識(shí)為replication的INSERT, UPDATE, DELETE語(yǔ)句。此后復(fù)制這些Transaction到Distributor,并寫(xiě)入distribution數(shù)據(jù)庫(kù)。最后Distribution Agent把Distributor上的Transaction運(yùn)送到Subscriber進(jìn)行重放。
注意:在圖中Distribution Agent運(yùn)行在Distributor上,這是在push(推)模式下的情況。可以配置為pull(拉)模式,Distribution Agent將運(yùn)行在Subscriber上。
更多關(guān)于Transactional Replication的原理可參考:
http://msdn.microsoft.com/en-us/library/ms151706(SQL.90).ASPx
項(xiàng)目中的配置與考量
在前文的系統(tǒng)結(jié)構(gòu)小節(jié),給出了原先的系統(tǒng)結(jié)構(gòu)。我們希望通過(guò)這次的項(xiàng)目得到如下所示的系統(tǒng)結(jié)構(gòu):

OliteReport能連接到一個(gè)由主數(shù)據(jù)庫(kù)復(fù)制出的單獨(dú)數(shù)據(jù)庫(kù)上,這樣這兩個(gè)庫(kù)之間的鎖就被隔離了。同時(shí)主數(shù)據(jù)庫(kù)與從數(shù)據(jù)庫(kù)安排在兩臺(tái)服務(wù)器上(項(xiàng)目中我們把復(fù)制出的數(shù)據(jù)庫(kù)放在了一臺(tái)虛擬機(jī)上),那么CPU資源與內(nèi)存資源的消耗也被隔離了。需要注意的是圖中OliteReport除了主要的讀操作外,還有少量的寫(xiě)操作(這是因?yàn)橛脩艨梢?a href=/pingce/cunchu/ target=_blank class=infotextkey>存儲(chǔ)Report條件)。我們把這些寫(xiě)指回主數(shù)據(jù)庫(kù),從數(shù)據(jù)庫(kù)在下一時(shí)刻的復(fù)制中得到這些數(shù)據(jù)。
在Transactional Replication中有三個(gè)邏輯角色,而項(xiàng)目中只有兩臺(tái)服務(wù)器。我們?nèi)绾蝸?lái)安排這三個(gè)邏輯角色呢?
- 候選的方案有兩種:1.主數(shù)據(jù)庫(kù)上配置Publisher和Distributor,從數(shù)據(jù)庫(kù)上配置Subscriber;2.主數(shù)據(jù)庫(kù)上只配置Publisher,從數(shù)據(jù)庫(kù)上配置Distributor和Subscriber。矛盾的焦點(diǎn)是Distributor放哪里?需要指出的是Distributor對(duì)于Replication非常重要,這個(gè)角色承擔(dān)著從主數(shù)據(jù)庫(kù)抓取Transaction的工作,在Push模式下,它還需要負(fù)責(zé)把Transaction推送到個(gè)Subscriber。這些工作都會(huì)消耗所在服務(wù)器的CPU和內(nèi)存資源。我們的項(xiàng)目希望盡可能保證業(yè)務(wù)模塊的性能,所以我們選用了方案2,把Distributor配置在從數(shù)據(jù)庫(kù)上。
我們是選用Push模式還是Pull模式呢?
- Push和Pull其實(shí)是針對(duì)Distributor傳送Transaction到Subscriber的方式而言的(這點(diǎn)我是很后面才認(rèn)識(shí)到的,開(kāi)始一直認(rèn)為Push或Pull會(huì)影響Distributor抓取Publisher上的信息,其實(shí)不然)。對(duì)于Distributor和Subscriber在一臺(tái)服務(wù)器上,這兩種模式的效果基本一樣。我們選擇了Pull模式,即Distribution Agent運(yùn)行在Subscriber端從Distributor拉Transaction數(shù)據(jù)。這是為了將來(lái)擴(kuò)展考慮,如果以后再加一臺(tái)服務(wù)器來(lái)作為Subscriber時(shí),Distributor不會(huì)增加太多的性能壓力。
另一個(gè)需要考慮的問(wèn)題是復(fù)制些什么?
- Transactional Replication可以選擇復(fù)制哪些表、存儲(chǔ)過(guò)程或函數(shù)等內(nèi)容。最簡(jiǎn)單的是把整個(gè)數(shù)據(jù)庫(kù)中的所以元素都進(jìn)行復(fù)制,但這會(huì)造成Replication服務(wù)所要監(jiān)視的對(duì)象很多,同時(shí)網(wǎng)絡(luò)上傳輸?shù)男畔⒘恳埠艽蟆m?xiàng)目中我們最后決定只復(fù)制所有的表,這樣做是出去性能的考慮。這樣做會(huì)對(duì)將來(lái)的release產(chǎn)生影響,需要注意,下文會(huì)進(jìn)行討論。
還有一個(gè)需要考慮的是如何進(jìn)行從數(shù)據(jù)庫(kù)的初始化?
- 在Transactional Replication開(kāi)始之前,首先要對(duì)從數(shù)據(jù)庫(kù)進(jìn)行初始化,使其獲得與主數(shù)據(jù)庫(kù)一致的表結(jié)構(gòu)和初始數(shù)據(jù)。在配置Transactional Replication中會(huì)有一個(gè)選項(xiàng)來(lái)進(jìn)行初始化(由Snapshot Agent完成)。但在我們的實(shí)驗(yàn)中初始化耗費(fèi)了幾個(gè)小時(shí),所以我們沒(méi)有使用Transactional Replication默認(rèn)的初始化方式,而是通過(guò)數(shù)據(jù)庫(kù)備份還原來(lái)完成初始化,要這樣做就需要改變配置的一些選項(xiàng),下文還會(huì)涉及。
Transactional Replication有些什么前提條件?
- 數(shù)據(jù)庫(kù)的Compatibility level(兼容性等級(jí))需要達(dá)到SQL Server 2005(90)(我們使用的是SQL Server 2005,當(dāng)兼容性級(jí)別為80時(shí),配置過(guò)程中會(huì)出現(xiàn)異常)。
- 數(shù)據(jù)庫(kù)的Recovery model(恢復(fù)模式)需要是Full(完整)。
- 所有需要Replicate的表必須具有主鍵。(這應(yīng)該是理所當(dāng)然的,但在這次配置中竟然發(fā)現(xiàn)一些非常“可恥”的東西)
- 存儲(chǔ)過(guò)程或其他腳本中,不能對(duì)進(jìn)行Replicate的表進(jìn)行truncate,需把相應(yīng)存儲(chǔ)過(guò)程中的語(yǔ)句改為delete。這是因?yàn)镽eplication是基于對(duì)Log的抓取與解析,但truncate不產(chǎn)生Log。
- 如果Replicate的元素還包括存儲(chǔ)過(guò)程或函數(shù),還會(huì)有其他一些前提條件,我們不在這里展開(kāi),可以查看msdn。
如何來(lái)配置Transactional Replication?
- 微軟提供了非常易用的圖形化界面可以進(jìn)行Replication的配置。但圖形化配置的靈活性是有限的,有些配置選項(xiàng)在圖形化界面下無(wú)法完成。我的建議是先用圖形化配置Replication,并生成相應(yīng)的script。此后根據(jù)需求修改script,并用script進(jìn)行配置。在我們的項(xiàng)目中也是這么做的。
- 默認(rèn)的情況下,Distributor服務(wù)器的D:/Program Files/Microsoft SQL Server/MSSQL.1/MSSQL/repldata會(huì)存放replicate數(shù)據(jù)。由于我們要支持Pull模式,需要共享這一文件夾,并給此文件夾設(shè)置一個(gè)具有Full Control權(quán)限的域賬戶。并把此域賬戶設(shè)置為Subscriber服務(wù)器上SQL Server Agent服務(wù)的運(yùn)行賬戶,此服務(wù)同時(shí)需要被設(shè)為Automatic啟動(dòng)方式。在sp_adddistpublisher的@working_directory參數(shù)設(shè)為此共享目錄的網(wǎng)絡(luò)路徑。
- 配置Publisher時(shí),sp_addpublication的參數(shù)@sync_method = N'concurrent', @repl_freq = N'continuous'保證了Replicate能盡可能實(shí)時(shí);@allow_initialize_from_backup = N’true’表示通過(guò)備份還原來(lái)進(jìn)行從數(shù)據(jù)庫(kù)的初始化。
- 配置Subscriber時(shí),sp_addsubscription的參數(shù)@sync_type = N'replication support only'表示從數(shù)據(jù)庫(kù)的初始化完全由外部來(lái)完成;@subscription_type = N'pull'表示使用拉模式。
后期維護(hù)
如何監(jiān)視Replication的性能與異常?
- 微軟提供了Replication Monitor。這個(gè)工具還是比較好用的,可以查看到Publication和Subscription的狀態(tài),還能查看到當(dāng)前有多少Transaction等待傳送。
- Transactional Replication設(shè)置好后,Distributor上將自動(dòng)生成相關(guān)的多個(gè)Alerts,如:Replication Warning: Subscription expiration (Threshold: expiration),Replication Warning: Transactional replication latency (Threshold: latency)等。可以將這些Alerts與Database Mail進(jìn)行綁定。當(dāng)出現(xiàn)警告時(shí),自動(dòng)發(fā)出郵件。(此功能雖然在項(xiàng)目中配置了,但從未正常發(fā)出警告郵件,一直不知道為什么,如果有人知道的話可以聯(lián)系我)。
如何進(jìn)行以后的Release?
- 原先數(shù)據(jù)庫(kù)的Release一般會(huì)分為三部分:1.表結(jié)構(gòu)的變化(包括加/刪表,加/刪列);2.配置數(shù)據(jù)的裝載(如添加新功能的配置數(shù)據(jù));3.刷函數(shù)與存儲(chǔ)過(guò)程腳本。
- 對(duì)于本項(xiàng)目中的Replication數(shù)據(jù)庫(kù),在Release過(guò)程中需注意以下幾點(diǎn):1.若新加的表需要進(jìn)行Replication,除了在主數(shù)據(jù)庫(kù)創(chuàng)建表之外,還需配置此表進(jìn)行Replicate,并進(jìn)行初始化。2.若要?jiǎng)h除某處于Replication的表,需先取消此表的Replication,再在主、從庫(kù)中drop此表。3.若需要加/刪Replication表的列(此列不能為主鍵列)時(shí),可以直接在主數(shù)據(jù)庫(kù)上執(zhí)行腳本,變化會(huì)自動(dòng)Replicate到從數(shù)據(jù)庫(kù)。4.配置數(shù)據(jù)的裝載也只需要在主數(shù)據(jù)庫(kù)完成。5.函數(shù)與存儲(chǔ)過(guò)程需要在主、從庫(kù)上都進(jìn)行刷新。
總結(jié)與設(shè)想
此項(xiàng)目已經(jīng)上線,基本達(dá)到了需求所提出的目標(biāo),但這只是開(kāi)始,優(yōu)化后的結(jié)構(gòu)給將來(lái)系統(tǒng)的擴(kuò)展提供了一個(gè)基礎(chǔ)。
- 通過(guò)實(shí)驗(yàn)發(fā)現(xiàn),在主/從數(shù)據(jù)庫(kù)上可以創(chuàng)建不同的索引而不互相干擾(這和Replication的配置相關(guān))。這就可以根據(jù)主、從數(shù)據(jù)庫(kù)不同的使用模式,創(chuàng)建更優(yōu)化的索引。我曾在國(guó)外某Blog上看到,利用SQL Server 2005的動(dòng)態(tài)視圖,自動(dòng)根據(jù)數(shù)據(jù)庫(kù)的使用模式來(lái)創(chuàng)建索引,就像自適應(yīng)索引機(jī)一樣。這也是我將在OliteReport數(shù)據(jù)庫(kù)上做的事。
- 將來(lái)如果有了多個(gè)Subscriber數(shù)據(jù)庫(kù),還能做OliteReport的數(shù)據(jù)庫(kù)Load Balance。當(dāng)有Report請(qǐng)求時(shí),系統(tǒng)首先查看各個(gè)Subscriber的CPU和Memory的Load,選擇Load較輕的Subscriber接受Report請(qǐng)求。
- 我們還能利用Replicate出的數(shù)據(jù)庫(kù)進(jìn)行BI(商業(yè)智能)分析與挖掘,而不會(huì)影響到主數(shù)據(jù)庫(kù)的運(yùn)行。
it知識(shí)庫(kù):SQL Server性能調(diào)優(yōu)——報(bào)表數(shù)據(jù)庫(kù)與業(yè)務(wù)數(shù)據(jù)庫(kù)分離,轉(zhuǎn)載需保留來(lái)源!
鄭重聲明:本文版權(quán)歸原作者所有,轉(zhuǎn)載文章僅為傳播更多信息之目的,如作者信息標(biāo)記有誤,請(qǐng)第一時(shí)間聯(lián)系我們修改或刪除,多謝。