|
|
本文根據InfoQ中文站對豆瓣洪強寧(@hongqn)的溝通交流整理而成。洪強寧介紹了豆瓣的架構和組件,并分享了豆瓣基礎平臺部的一些團隊經驗。文中截圖來自洪強寧在2013年CTO俱樂部中的分享。
架構

豆瓣整個基礎架構可以粗略的分為在線和離線兩大塊。在線的部分和大部分網站類似:前面用LVS做HA,用Nginx做反向代理,形成負載均衡的一層;應用層主要是做運算,將運算結果返回給前面的用戶,DAE平臺是這兩年建起來的,現在大部分豆瓣的應用基本都跑在DAE上面了;應用后面的基礎服務也跟其他網站差不多,MySQL、memcached、redis、beanstalkd,不一樣的是NoSQL的選擇——BeansDB,這是我們在幾年前開源的KV數據庫,也是國內比較早開源的KV數據庫。
BeansDB項目可以說是一個簡化版的AWS DynamoDB,該項目在2008年啟動,2009年開源,第?版使?tokyo cabiNET作為存儲引擎,2010年使?bitcask存儲格式重寫了存儲引擎,性能更好。BeansDB對key做哈希運算找到節點來實現分布和冗余, 一個寫操作會寫好幾個節點,而現在的配置是寫三份讀一份。BeansDB主要的特點是支持海量KV數據庫——相比Redis這種支持幾十個G到幾百個G的內存KV數據庫,BeansDB可以支持到上百T的數據。另外BeansDB最大的好處就是運維很簡單,性能、可用性、擴容都很好,也實現了最終一致性。
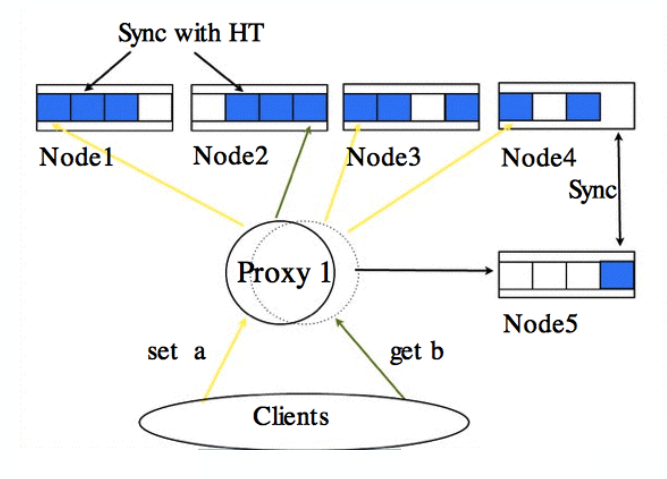
BeansDB中間的Proxy是用Go語言寫的,也是一個開源的組件。整體來說BeansDB的設計結構比較簡單,相比Redis那種有多種value類型的方式,BeansDB的value比較簡單一些。
在豆瓣內部建立了兩個不同的BeansDB集群,一個是doubandb,一個是doubanfs,分別針對不同的場景。doubandb主要存儲小型文本數據,如影評、用戶個人介紹、帖子內容等,這樣的好處是可以大大降低我們對MySQL的性能依賴,算是給MySQL減負;doubanfs主要存放圖片和音頻等中型數據。
DAE可以說是基于很多以前積累的、舊的組件做起來的。我們做的這種對內的PaaS,相比對外的PaaS而言做了很多簡化,尤其是安全方面如應用間隔離、權限管理方面,我們都不用像公有云那樣花大量精力去做,所以工作量其實還好。DAE現在在計劃開源,當然它現在只支持Python應用。以后我們也許會讓DAE支持Go語言。
上面是在線的部分,對高可用性和低時延有較大要求。離線部分則包括數據挖掘、數據分析等,技術組件分別是海量分布式文件系統MooseFS,這個文件系統的結構類似HDFS,用C語言編寫,其好處在于FUSE模塊實現的比較好,用文件系統就可以直接進行操作,而不需要專門的命令,可以支持的數據量也很大。另外就是自己開發的分布式計算平臺DPark。
DPark顧名思義是Spark的Python實現,不過現在已經跟Spark越來越不一樣了。和Hadoop 相比,Spark可以使用內存做為緩存加速分布式計算,DPark繼承了這個優點,這對于大規模數據的迭代計算非常有用。在豆瓣的應用場景下,因為我們的離線計算很多是推薦算法計算,這種計算涉及大量的迭代算法,如果每次計算的結果都入磁盤再在下一輪計算加載,那性能是很差的,所以DPark能夠大幅提升性能。另外,因為DPark的編寫使用了函數式語言的特點,所以可以寫的非常簡潔:

到目前(2014年3月),DPark的集群規模和處理數據量已經比去年多了一倍左右,一天要處理60~100TB左右的數據。
團隊
當前,我所負責的豆瓣平臺部一共包括四個部分:核心系統,這塊也是由我直接帶領的,共6名工程師;DAE,現在是彭宇負責,共4名工程師;DBA兩人;SA兩人。
平臺部負責的項目大多是跟業務無關的東西,貼近應用層的主要在產品線團隊做,這個分工跟豆瓣工程團隊的發展歷史有關。早期豆瓣工程師還不多的時候,就已經分為兩種傾向,一種是偏業務的,就是去做用戶能看得見的東西;另一種是支持性的,運行在業務層下面、不被用戶所感知的東西。下面這一層就衍變成了平臺部門。
在豆瓣,不管是做產品還是做平臺的工程師,技術實力都比較強,一個項目應該從哪個部門發起,并不是看這個任務的難度,而是看它是公共的還是業務特有的。有些項目即使未來可能會成為公共的,但一開始只是一個產品線需要,那么它也會從產品線發起。比如豆瓣的短信服務,最開始是產品線有需求,所以這些服務都是由他們發起完成的,平臺這邊主要負責提供建設服務的架構,比如DoubanService,告訴他們一個服務怎樣去寫、怎樣去部署、怎樣去對用戶開放。短信服務后來成為很多產品線都在使用的服務,同時這個系統本身也越來越成熟,那么它逐漸就被轉移到SA團隊來進行維護。
核心系統組做過的項目,包括剛才提到的DPark、BeansDB,還有MooseFS這些二次開發的,還有搜索服務、信息推送的長連接服務等,大大小小差不多有十幾個。有些項目處于維護狀態,所以需要的人不是那么多。
跟豆瓣其他工程團隊一樣,平臺部也強制大家做code review。這對于核心系統來說很重要的一點在于,code review是一個知識共享的過程:我們人少項目多,所以很多項目都是一個人做主力,很容易就變成其他人不知道你這個項目具體是什么情況,而強制code review就可以實現一種公開透明的狀態,讓大家都了解每個項目在做什么。
在平臺部,因為你做的所有東西都會影響到全公司,測試顯然很重要,我們還做了另一件事來進行質量保證,那就是一個項目由誰來主導上線,誰就要負責這個項目的故障響應——所有運維、調整系統等SA的工作,你這個第一負責人都要參與。你做的東西的好壞會影響到自己晚上能不能睡好覺,所以大家就會比較謹慎。灰度上線也是我們這邊的通用做法。
平臺部還有一點跟產品線不一樣的是,平臺部沒有產品經理,所以你的工作方向更多是自己去找的,每個人自己發現問題的能力更重要。我們每個月都會問大家,你這個月想要解決什么問題?如果方向大家一致認可,那就去做。
最后,對于新技術的引入上,豆瓣整體是比較偏激進的,我們鼓勵大家去看看新的技術。當然我們也不會看到新的就上,這里面有一些限制:一個是比較重要的服務如果要上新的技術,一定要有成功案例,且成功案例有跟我們量級差不多的規模,這樣可以降低風險;另一個是對于引入的新技術一定要吃透——大部分引入的技術肯定是要做二次開發的,所以拿進來的技術你必須保證能完全理解它的代碼結構,出了問題能修,能去掉自己無法掌控的東西。這也是為什么豆瓣不太可能在重要的地方引入Java的原因,除非別無選擇,我們一般都是Python、C和Go。
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播更多信息之目的,如作者信息標記有誤,請第一時間聯系我們修改或刪除,多謝。