|
|
復(fù)制代碼 代碼如下:
<script language=”Javascript”>
var stock_code = stockcode.innerText;
var stock_code = stockcode.innerHTML;
</script>
<div id="stockcode" style="display:none">
test
</div>
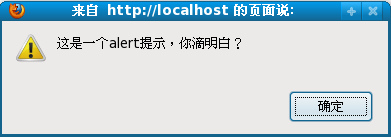
innerText 跟 innerHTML是兩個(gè)非DOM標(biāo)準(zhǔn)的方法
其區(qū)別如圖所示:
(圖中應(yīng)該為innerText)

在IE中 innerText 跟 inner HTML 兩個(gè)方法都能正常運(yùn)行
但是FF里面的innerText不可用,但是有一個(gè)替代方法: textContent
IE: oDiv.innerText = aString; oDiv.innerHTML = aString;
FF: oDiv.textContent = aString; oDiv.innerHTML = aString;
Ajax in action 的作者之一Eric 用正則表達(dá)式 實(shí)現(xiàn)了 一個(gè)兼容方法,比較有趣
Hope this helps
A little smirk
One day a secretary is leaving on her lunch break, and she notices her boss standing in front of a shredder with a clueless look on his face. The secretary walks up to him and asks if he needs help.
"Yes!" he says looking and sounding relieved, "This is very important."
Glad to help, she turns the shredder on and inserts the paper. Then her boss says, "Thanks, I only need one copy."
Create function like innerText
As you may have figured out innerText is IE only. That means that browsers like Mozilla, Firefox, and NETscape will return undefined. If you do not know what innerText does, it strips out all of the tags so you only see the text.
For example, if a div contains the HTML <span id='span1'>Eric</span>, innerHTML would return <span id='span1'>Eric</span> while innerText will return Eric.
Now to make innerHTML act the same we need to use some regular expressions with the strings replace() method.
Now the basic pattern we need to match is or or or
Now the regular expression we need to use is /<//?[^>]+>/gi
If you do not know regular expressions here is a quick explanation:
/ - Starts the regular expression
< - Match the less than sign
// - Escape the character / so it can be matched (Without the / you would be saying it is the end of the reg exp.)
? - Match the / character 0 or 1 times
[^>] - Match any character but greater than sign
+ - Match [^>] one or more times
> - Match greater than sign
/ - End the regular expression
gi - Tells regular expression to match global and ignore the case
So now the function to replace the text would look like:
復(fù)制代碼 代碼如下:
<script type="text/Javascript">
var regExp = /<//?[^>]+>/gi;
function ReplaceTags(xStr){
xStr = xStr.replace(regExp,"");
return xStr;
}
</script>
All you need to do is pass it a string and it returns the string stripped of the tags.
An example is shown below to grab the text from a div without the tags.
[Ctrl+A 全選 注:如需引入外部Js需刷新才能執(zhí)行]
JavaScript技術(shù):javascript獲取div的內(nèi)容 精華篇,轉(zhuǎn)載需保留來(lái)源!
鄭重聲明:本文版權(quán)歸原作者所有,轉(zhuǎn)載文章僅為傳播更多信息之目的,如作者信息標(biāo)記有誤,請(qǐng)第一時(shí)間聯(lián)系我們修改或刪除,多謝。